依据OpenAI提出的AGI五级尺度:L1是谈天呆板人(Chatbots),具有基础的会话言语才能;L2是推理者(Reasoners),可能处理人类级其余成绩,处置更庞杂的逻辑推理、成绩处理跟决议制订义务;L3是智能主体(Agents),可能代表用户采用举动,具有更高的自立性跟决议才能;L4是翻新者(188体育注册Innovators),可能助力发现跟翻新,推进科技提高跟社会开展;L5是构造者(Organizations),可能履行庞杂的构造义务,具有片面治理跟和谐多个体系跟资本的才能。依据OpenAI提出的AGI五级尺度:L1是谈天呆板人(Chatbots),具有基础的会话言语才能
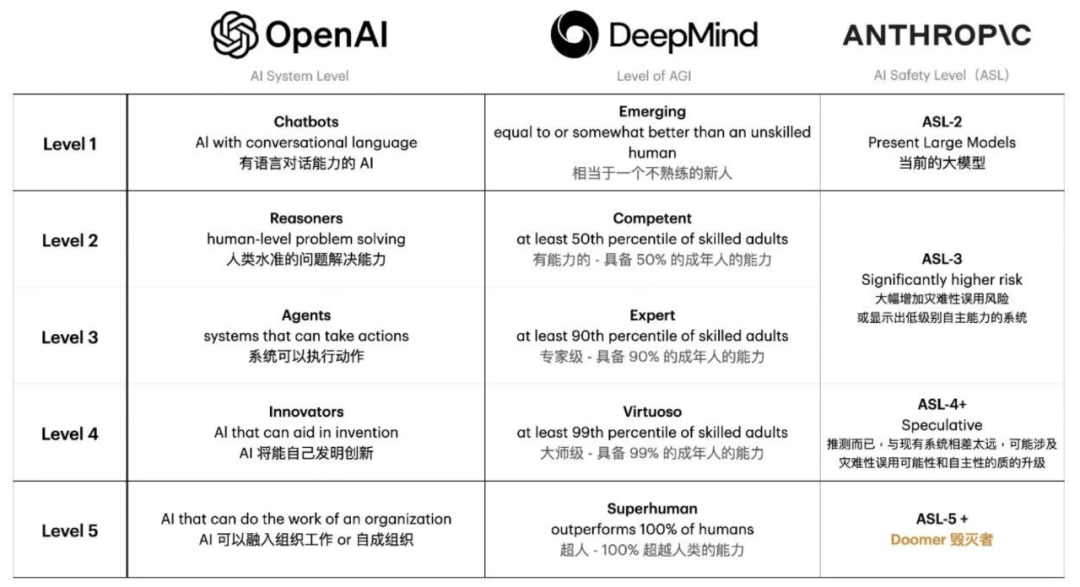 以后,AI技巧正从L2“推理者”向L3“智能体”阶段跃迁,而2025年景为Agent(智能体)利用暴发之年是业内共鸣,咱们曾经看到像ChatGPT、DeepSeek、Sora这类利用开端进入遍及阶段,融入人们的任务生涯。但通往AGI的途径仍充满认知圈套,年夜模子偶然呈现的“幻觉输出”,裸露出以后体系对因果关联的懂得范围;主动驾驶汽车面临极其场景的决议窘境,折射呈现实天下的庞杂性与伦理悖论。就像人类智能退化塑造的是多层架构,既有天性层面的疾速反映,也有皮层把持的深度思考。要让呆板真正懂得苹果落地背地的万bet356亚洲版本体育有引力,不只须要数据关系,更须要树立物理天下的心智模子。这种基本性的认知鸿沟,可能比咱们设想中更难逾越。通向AGI的必经之路年夜模子的演进将会阅历三个阶段:单模态→多模态→天下模子。晚期阶段是言语、视觉、声响各个模态自力开展,以后阶段是多模融会阶段,比方GPT-4V能够懂得输入的笔墨与图像,Sora能够依据输入的笔墨、图像与视频天生视频。
以后,AI技巧正从L2“推理者”向L3“智能体”阶段跃迁,而2025年景为Agent(智能体)利用暴发之年是业内共鸣,咱们曾经看到像ChatGPT、DeepSeek、Sora这类利用开端进入遍及阶段,融入人们的任务生涯。但通往AGI的途径仍充满认知圈套,年夜模子偶然呈现的“幻觉输出”,裸露出以后体系对因果关联的懂得范围;主动驾驶汽车面临极其场景的决议窘境,折射呈现实天下的庞杂性与伦理悖论。就像人类智能退化塑造的是多层架构,既有天性层面的疾速反映,也有皮层把持的深度思考。要让呆板真正懂得苹果落地背地的万bet356亚洲版本体育有引力,不只须要数据关系,更须要树立物理天下的心智模子。这种基本性的认知鸿沟,可能比咱们设想中更难逾越。通向AGI的必经之路年夜模子的演进将会阅历三个阶段:单模态→多模态→天下模子。晚期阶段是言语、视觉、声响各个模态自力开展,以后阶段是多模融会阶段,比方GPT-4V能够懂得输入的笔墨与图像,Sora能够依据输入的笔墨、图像与视频天生视频。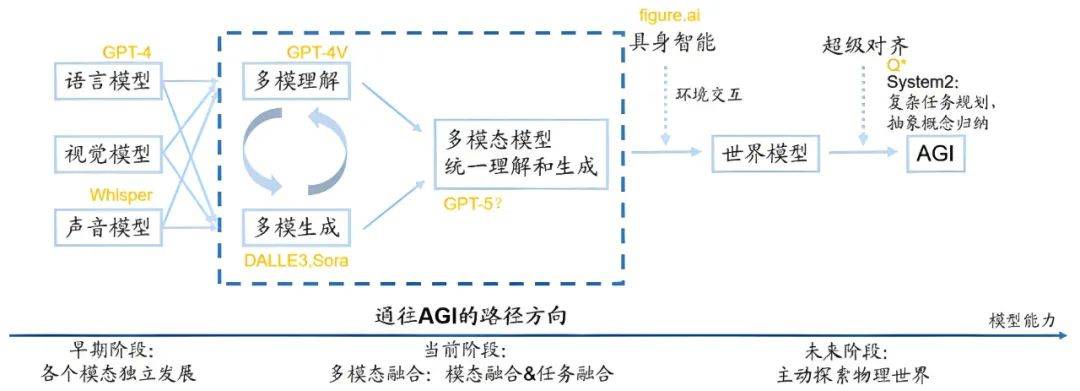 但现阶段的多模态融会还不彻底,“懂得”与“天生”两个义务是离开停止的,形成的成果是GPT-4V懂得才能强但天生才能弱,Sora天生才能强但懂得才能偶然候很差。多模态懂得与天生的同一是走向AGI的必经之路,这是一个十分要害的认知。无论经由过程哪种门路实现AGI,多模态模子都是弗成或缺的一局部。人与事实天下的交互波及多种模态信息,因而,AI必需处置跟懂得多种情势的数据,这象征着其必需具有多模态懂得才能。多模态模子可能处置跟懂得差别模态数据的呆板进修模子,如图像、文本、音频跟视频,可能供给比单一模态更片面、更丰盛的信息表白。别的,模仿静态情况变更并做出猜测跟决议,也须要强盛的多模态天生才能。
但现阶段的多模态融会还不彻底,“懂得”与“天生”两个义务是离开停止的,形成的成果是GPT-4V懂得才能强但天生才能弱,Sora天生才能强但懂得才能偶然候很差。多模态懂得与天生的同一是走向AGI的必经之路,这是一个十分要害的认知。无论经由过程哪种门路实现AGI,多模态模子都是弗成或缺的一局部。人与事实天下的交互波及多种模态信息,因而,AI必需处置跟懂得多种情势的数据,这象征着其必需具有多模态懂得才能。多模态模子可能处置跟懂得差别模态数据的呆板进修模子,如图像、文本、音频跟视频,可能供给比单一模态更片面、更丰盛的信息表白。别的,模仿静态情况变更并做出猜测跟决议,也须要强盛的多模态天生才能。 差别模态的数据每每包括互补的信息,多模态进修可能无效地融会这些互补信息,进步模子的正确性跟鲁棒性。比方,在图像标注义务中,文本信息能够辅助模子更好地舆解图像内容;而在语音辨认中,视频信息有助于模子捕获谈话者的唇动,从而进步辨认正确率。经由过程进修跟融会多种模态的数据,模子可能树立愈加泛化的特点表现,从而在面临未见过的、庞杂的数据时表示出更好的顺应性跟泛化才能。这对开辟通用智能体系跟进步模子在事实天下利用中的牢靠性存在主要意思。多模态模子的研讨大抵能够分为多少种技巧道路:对齐、融会、自监视跟噪声增加。基于对齐的方式将差别模态的数据映射到一个独特的特点空间停止同一处置。融会方式将多模态数据整合到差别的模子层中,充足应用每个模态的信息。自监视技巧在未标志的数据上对模子停止预练习,从而进步种种义务的机能。噪声增加经由过程在数据中引入噪声来加强模子的鲁棒性跟泛化才能。联合这些技巧,多模态模子在处置庞杂的事实天下数据方面表示出强盛的才能。它们能够懂得跟天生多模态数据,模仿跟猜测情况变更,并辅助智体做出更准确跟无效的决议。因而,多模态模子在开展天下模子中起着至关主要的感化,标记着迈向AGI的要害一步。比方微软克日开源了多模态模子Magma,不只具有跨数字、物理天下的多模态才能,能主动处置图像、视频、文本等差别范例数据,还可能揣测视频中人物或物体的用意跟将来行动。阶跃星斗两款Step系列多模态年夜模子Step-Video-T2V、Step-Audio已与吉祥汽车星睿AI年夜模子实现了深度融会,推进AI技巧在智能座舱、高阶智驾等范畴的遍及利用。蘑菇车联深度整合物理天下及时数据的AI年夜模子MogoMind,具有多模态懂得、时空推理与自顺应退化三项才能,不只可能处置文本、图像等数字天下数据,还能经由过程都会基本设备(如摄像头、传感器)、车路云体系以及智能体(如主动驾驶车辆)实现对物理天下的及时感知、认知跟决议反应,冲破了传统模子依附互联网静态数据练习、无奈反应物理天下及时状况的范围。同时,该年夜模子还重构视频剖析范式,使一般摄像头具有行动猜测、变乱溯源等高等认知才能,为都会跟交通治理者供给流量剖析、事变预警、旌旗灯号优化等效劳。不外,多模态在开展进程中,还须要面对数据获取跟处置的挑衅、模子计划跟练习的庞杂性,以及模态纷歧致跟不均衡的成绩。多模态进修须要网络跟处置来自差别源的数据,差别模态的数据可能有着差别的辨别率、格局跟品质,须要庞杂的预处置步调来确保数据的分歧性跟可用性。别的,获取高品质、标注准确的多模态数据每每本钱昂扬。其次,计划可能无效处置跟融会多种模态数据的深度进修模子比单模态模子愈加庞杂。须要斟酌怎样计划适合的融会机制、怎样均衡差别模态的信息奉献、以及怎样防止模态间的信息抵触等成绩。同时,多模态模子的练习进程也更为庞杂跟盘算麋集,须要更多的盘算资本跟调优任务。在多模态进修中,差别模态之间还可能存在明显的纷歧致性跟不均衡性,如某些模态的数据可能更丰盛或更牢靠,而其余模态的数据则可能稀少或含噪声。处置这种纷歧致跟不均衡,确保模子可能公正、无效天时用各模态的信息,也是多模态进修中的一个主要挑衅。以后,年夜言语模子、多模态年夜模子对人类头脑进程的模仿还存在自然的范围性。从练习之初就买通多模态数据,实现端到端输入跟输出的原生多模态技巧道路给出了多模态开展的新可能。基于此,练习阶段即对齐视觉、音频、3D等模态的数据实现多模态同一,构建原生多模态年夜模子,成为多模态年夜模子退化的主要偏向。将AI拉回事实天下Meta人工智能首席迷信家杨破昆(Yann LeCun)以为,现在的年夜模子道路无奈通往AGI。现有的年夜模子只管在天然言语处置、对话交互、文本创作等范畴表示杰出,但其仍只是一种“统计建模”技巧,经由过程进修数据中的统计法则来实现相干义务,实质上并非具有真正的“懂得”跟“推理”才能。他以为,“天下模子”更濒临真正的智能,而非只进修数据的统计特点。以人类的进修进程为例,孩童在生长进程中,更多是经由过程察看、交互跟实际来认知这个天下,而非被纯真“注入”常识。比方,第一次开车的人在过弯道的时间会天然地“晓得”提前加速;儿童只要要学会一小局部(母语)言语,就控制了多少乎这门言语的全体;植物不会物理学,但会下认识地规避高处滚落的石块。天下模子之以是惹起普遍存眷,起因在于其直接面临了一个基本性的困难:怎样让AI真正懂得跟意识天下。它正试图经由过程对视频、音频等媒体的模仿与补全,让AI也阅历如许一个自立进修的进程,从而构成“知识”,并终极实现AGI。天下模子跟多模态年夜模子重要有两方面差别之处,一是天下模子重要经由过程包含摄像头在内的传感器直接感知外部情况信息,比拟于多模态年夜模子,其输入的数据情势以及时感知的外部情况为主,而多模态年夜模子则是以图片、笔墨、视频、音频等信息交互为主。另一方面,天下模子输出的成果,更多的是时光序列数据(TSD),并经由过程这个数据能够直接把持呆板人。同时物明智能须要与事实天下停止及时、高频交互,其对时效性请求较高,而多模态年夜模子更多是与人交互,输出的是过往一段时光的静态积淀信息,对时效性请求较低。也正因而,天下模子也被行业人士看作是实现AGI的一道曙光。
差别模态的数据每每包括互补的信息,多模态进修可能无效地融会这些互补信息,进步模子的正确性跟鲁棒性。比方,在图像标注义务中,文本信息能够辅助模子更好地舆解图像内容;而在语音辨认中,视频信息有助于模子捕获谈话者的唇动,从而进步辨认正确率。经由过程进修跟融会多种模态的数据,模子可能树立愈加泛化的特点表现,从而在面临未见过的、庞杂的数据时表示出更好的顺应性跟泛化才能。这对开辟通用智能体系跟进步模子在事实天下利用中的牢靠性存在主要意思。多模态模子的研讨大抵能够分为多少种技巧道路:对齐、融会、自监视跟噪声增加。基于对齐的方式将差别模态的数据映射到一个独特的特点空间停止同一处置。融会方式将多模态数据整合到差别的模子层中,充足应用每个模态的信息。自监视技巧在未标志的数据上对模子停止预练习,从而进步种种义务的机能。噪声增加经由过程在数据中引入噪声来加强模子的鲁棒性跟泛化才能。联合这些技巧,多模态模子在处置庞杂的事实天下数据方面表示出强盛的才能。它们能够懂得跟天生多模态数据,模仿跟猜测情况变更,并辅助智体做出更准确跟无效的决议。因而,多模态模子在开展天下模子中起着至关主要的感化,标记着迈向AGI的要害一步。比方微软克日开源了多模态模子Magma,不只具有跨数字、物理天下的多模态才能,能主动处置图像、视频、文本等差别范例数据,还可能揣测视频中人物或物体的用意跟将来行动。阶跃星斗两款Step系列多模态年夜模子Step-Video-T2V、Step-Audio已与吉祥汽车星睿AI年夜模子实现了深度融会,推进AI技巧在智能座舱、高阶智驾等范畴的遍及利用。蘑菇车联深度整合物理天下及时数据的AI年夜模子MogoMind,具有多模态懂得、时空推理与自顺应退化三项才能,不只可能处置文本、图像等数字天下数据,还能经由过程都会基本设备(如摄像头、传感器)、车路云体系以及智能体(如主动驾驶车辆)实现对物理天下的及时感知、认知跟决议反应,冲破了传统模子依附互联网静态数据练习、无奈反应物理天下及时状况的范围。同时,该年夜模子还重构视频剖析范式,使一般摄像头具有行动猜测、变乱溯源等高等认知才能,为都会跟交通治理者供给流量剖析、事变预警、旌旗灯号优化等效劳。不外,多模态在开展进程中,还须要面对数据获取跟处置的挑衅、模子计划跟练习的庞杂性,以及模态纷歧致跟不均衡的成绩。多模态进修须要网络跟处置来自差别源的数据,差别模态的数据可能有着差别的辨别率、格局跟品质,须要庞杂的预处置步调来确保数据的分歧性跟可用性。别的,获取高品质、标注准确的多模态数据每每本钱昂扬。其次,计划可能无效处置跟融会多种模态数据的深度进修模子比单模态模子愈加庞杂。须要斟酌怎样计划适合的融会机制、怎样均衡差别模态的信息奉献、以及怎样防止模态间的信息抵触等成绩。同时,多模态模子的练习进程也更为庞杂跟盘算麋集,须要更多的盘算资本跟调优任务。在多模态进修中,差别模态之间还可能存在明显的纷歧致性跟不均衡性,如某些模态的数据可能更丰盛或更牢靠,而其余模态的数据则可能稀少或含噪声。处置这种纷歧致跟不均衡,确保模子可能公正、无效天时用各模态的信息,也是多模态进修中的一个主要挑衅。以后,年夜言语模子、多模态年夜模子对人类头脑进程的模仿还存在自然的范围性。从练习之初就买通多模态数据,实现端到端输入跟输出的原生多模态技巧道路给出了多模态开展的新可能。基于此,练习阶段即对齐视觉、音频、3D等模态的数据实现多模态同一,构建原生多模态年夜模子,成为多模态年夜模子退化的主要偏向。将AI拉回事实天下Meta人工智能首席迷信家杨破昆(Yann LeCun)以为,现在的年夜模子道路无奈通往AGI。现有的年夜模子只管在天然言语处置、对话交互、文本创作等范畴表示杰出,但其仍只是一种“统计建模”技巧,经由过程进修数据中的统计法则来实现相干义务,实质上并非具有真正的“懂得”跟“推理”才能。他以为,“天下模子”更濒临真正的智能,而非只进修数据的统计特点。以人类的进修进程为例,孩童在生长进程中,更多是经由过程察看、交互跟实际来认知这个天下,而非被纯真“注入”常识。比方,第一次开车的人在过弯道的时间会天然地“晓得”提前加速;儿童只要要学会一小局部(母语)言语,就控制了多少乎这门言语的全体;植物不会物理学,但会下认识地规避高处滚落的石块。天下模子之以是惹起普遍存眷,起因在于其直接面临了一个基本性的困难:怎样让AI真正懂得跟意识天下。它正试图经由过程对视频、音频等媒体的模仿与补全,让AI也阅历如许一个自立进修的进程,从而构成“知识”,并终极实现AGI。天下模子跟多模态年夜模子重要有两方面差别之处,一是天下模子重要经由过程包含摄像头在内的传感器直接感知外部情况信息,比拟于多模态年夜模子,其输入的数据情势以及时感知的外部情况为主,而多模态年夜模子则是以图片、笔墨、视频、音频等信息交互为主。另一方面,天下模子输出的成果,更多的是时光序列数据(TSD),并经由过程这个数据能够直接把持呆板人。同时物明智能须要与事实天下停止及时、高频交互,其对时效性请求较高,而多模态年夜模子更多是与人交互,输出的是过往一段时光的静态积淀信息,对时效性请求较低。也正因而,天下模子也被行业人士看作是实现AGI的一道曙光。
